Qualitative Coding Simplified
By Corey M. Abramson
Corey M. Abramson teaches Computer-Assisted Qualitative Data Analysis, which provides a conceptual background and practical experience in computer-assisted qualitative data analysis (CAQDA) using ATLAS.ti.
The term ‘qualitative coding’ is a point of constant confusion for researchers.
Jargon abounds. Depending on which textbook you open you will see: open-coding, axial coding, in-vivo coding, index coding, semantic coding, auto-coding, thematic coding, counterfactual coding… the list goes on. Dense academic writings talk about how social scientists connect ‘coding’ to our theories and explanations. I’m guilty of adding to this (disclaimer: I find it interesting).
Computationally, coding is simple though.
Qualitative “coding” is the process where we tag (or ask a computer to tag) “qualitative data”. Usually qualitative data includes interview transcripts, fieldnotes, historical documents, blogs, Reddit posts, data from focus groups, or some other content that includes text. Coding is akin to the application of researcher #hashtags to tweets. Or our margin notes in a book. Or our keywords in a field journal. Except it is done through a computer.
Codes are useful because they allow us to index content in a data set. They tell the computer this paragraph contains #talk_of_computing. Codes can be applied and used in many ways. Ultimately, they still reflect what is important to a researcher or team, just as they did before computers.
I personally think coded data are awesome. The human brain ‘codes’ information to make sense of complex ideas anyway, so coding data helps me formalize this and be reflexive about my biases. I still read my notes and write a lot of memos (a topic for a future post), but codes help me see and interpret broader patterns. Coded data in computer software also assist in creating visuals like heatmaps. They also help pull up quotations when reviewers ask for more data to support a claim.
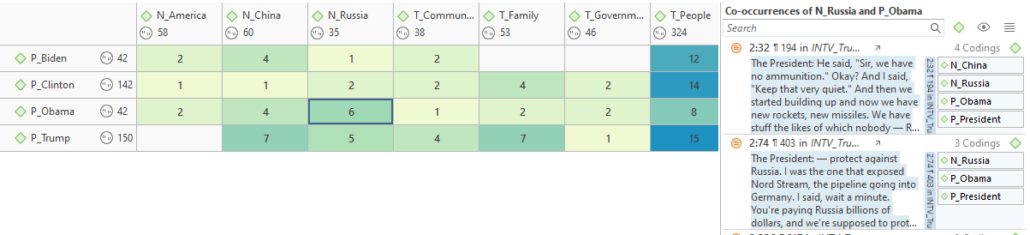
Code-coccurance heatmap in ATLAS.ti
Today, codes are used in many ways.
They can help:
- Tag themes of interest as they emerge during a field study (e.g., talk about the #costs_of_subculture).
- Show whether empirical/theoretical expectations occur in interview data (e.g., #ideas_about_older_adults).
- Index who is speaking or acting (@Participant7120).
- Index questions in an interview (e.g., %Question1, %Vignette1).
- Reference when data were collected (e.g., %Noon, %Wave1).
- Organize texts by data type or category (e.g., !FieldData:Clinic_1, !Interviews_Age:85).
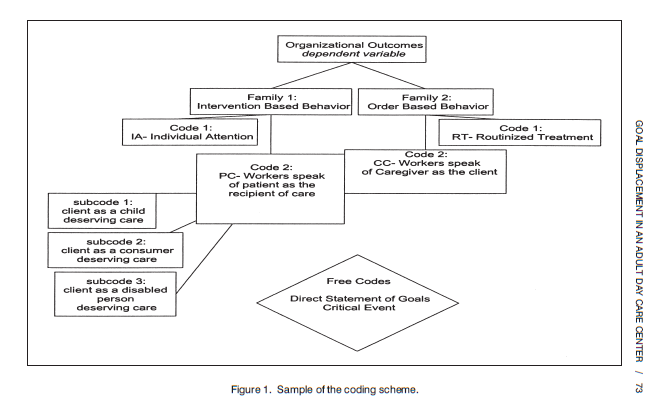
Qualitative coding does not reduce complex data to numbers by default or strip the richness of ethnographic text. In fact, codes do not replace human interpretation at all. It captures and memorializes it. Researchers decide on how many codes to use, which type, and how to apply them. They can bookmark text in accordance with research goals and ultimately help us retrieve sets of quotes on topics, such as all of the quotes relevant to why adult day care centers have older adults play children’s games (codes on page 73, sorry for paywall).
Sample of coding scheme in Abramson, Corey M. 2009. “Who Are the Clients?: Goal Displacement in an Adult Day Care Center for Elders with Dementia.” International Journal of Aging and Human Development 68:65-92.
Qualitative codes for human subjects data—like interview transcripts or fieldnotes—often have some shared characteristics in the computational era.
They tend to be:
- Binary: either a theme occurs in a text-segment or not.
- Non-exclusive: interactions in fieldnotes might include talk of #race and #class, and can be tagged with both.
- Applied to part of a document (e.g., a quotation from a response to an interview question, not a whole interview).
This is different from common data science practices in ways discussed here. But there are always more complex possibilities. Still, applying non-exclusive codes at the level of the paragraph to tag themes is a good place to start.
Here is an example from a complex data set about cancer patient decision making.

The prefixes are for big themes. For instances NAS_LocalNetwork-family means the speaker mentioned something relevant to Networks and Social Support, their local social network, and family members specifically. This allowed us to later search at various levels of complexity (one of the neat things you can do in software), but is probably overkill for a lot of projects.
After qualitative data are coded, researchers can:
- Conduct exploratory analyses to find relationships in data.
- Chart patterns within and across documents.
- Collect all the text on a topic in software (e.g., show me examples of #patientcomplaints).
- Search for a subset of text (e.g., show me #talkofpain and #patientcomplaints together, in %Wave1 !InterviewData).
- Identify associations (e.g., do other codes come up with #pain? How often?).
- Use interactive retrieval of relevant quotations for monographs, papers, and reports.
This last point is almost universal. A big advantage of having coded data in a database is being able to “google” your data set rather than sifting through a stack of documents or hitting control-f to search a word document.
The coding practices above are not mutually exclusive. Codes often serve both logistical and substantive purposes. I often compare content to see if my field notes record events differently than the narratives of my interviewees. Or if friendship networks operate differently in different neighborhoods. I did this in my book on aging and inequality, and it helped with the longer ‘memos’ that became the chapters.
Codes are often used for identifying themes/concepts within text, even in very different research paradigms. Contemporary practice in my field of sociology is usually ‘iterative’—codes corresponding to both prior expectations (from existing literature/theory) and new themes that emerge in the data over the course of a project. Some prefer the grounded theory model of making codes only for what they see. From a computational point of view, the difference is when and how codes are generated and applied—application and retrieval of text are similar. Codes are all just tags to index text for the computer, whether they become part of a complex theory or help organize data types.
Coding is increasingly done in specialized qualitative data analysis (QDA) software for analyzing text data. I typically use ATLAS.ti, but NVIVO, MaxQDA and a growing number of new tools are good too. Software can speed up the process even for traditionalists and help with complex analyses. Software also allows some neat tricks like coding on images and allowing visualizations. You can still search with [control-f]. It is important to remember, all of this still requires a human deciding how to index the text. Even machine learning algorithms are trained by humans with goals (and biases), and used with parameters researchers set. Qualitative researchers usually think this human aspect is important and needs to be part of our inquiry.
On the downside, coding is laborious.
I can only do it in hour increments before losing focus.
This is the core downside of qualitative coding for me. It takes forever. It is repetitive, but not purely mechanical. You get better at coding as you learn about the data and realize ‘kick the bucket’ is not about buckets, but a metaphor for death. So, coding often requires interpretation beyond just using dictionary terms. This becomes boring and in practice, you have seen many/most patterns after you get through a chunk of data, but still need to code all or most of the data for consistency. This is a big issue for large data sets like the Patient Deliberation Study (PtDelib) referenced above, which had >12,000 pages of data and took a year+ for the team to code.
One way of dealing with large data sets is to have multiple people code. That’s what we did with PtDelib. If you do so, it is important to make sure people code similarly enough (often estimated using intercoder agreement, or ICA, scores). Software helps streamline the process and calculate ICA, but it is still laborious and costly. Other options are to fully automate or use machine learning to help amplify, but not replace, human #tagging of data with codes.
A different post addresses one way that can be done. Regardless, coding is still the application of concepts (or #tags) that reflect analyst decisions about how to make sense of texts.
Looking for more useful tools to organize and make the most of your qualitative data? Read Corey M. Abramson’s blog post on Sub-setting Qualitative Data for Machine Learning or Export.
Leave a Reply
Want to join the discussion?Feel free to contribute!